Berikut materi-materi yang telah saya pelajari selama semester 2 + source code.
Linked list merupakan sebuah struktur data yang digunakan untuk menyimpan sejumlah objek data biasanya secara terurut sehingga memungkinkan penambahan, pengurangan, dan pencarian atas elemen data yang tersimpan dalam linked list dilakukan secara lebih efektif. Pada praktiknya sebuah struktur data memiliki elemen yang digunakan untuk saling menyimpan rujukan antara satu dengan lainnya sehingga membentuk sebuah linked list abstrak, tiap-tiap elemen yang terdapat pada linked list abstrak ini seringkali disebut sebagai node. karena mekanisme rujukan yang saling terkait inilah disebut sebagai linked list. Biasanya didalam suatu linked list, terdapat istilah head dan tail.
- Head adalah elemen yang berada pada posisi pertama dalam suatu linked list
- Tail adalah elemen yang berada pada posisi terakhir dalam suatu linked list
Kerugian memakai linked list :
- memerlukan lebih banyak memori karena penyimpanan menggunakan pointer
- node di linked list harus dibaca berurutan dari awal
Keuntungan memakai linked list :
- linked list bersifat dinamis, hanya mengalokasikan memori saat diperlukan
- menambahkan dan menghapus dapat dilakukan dengan mudah
- waktu akses cepat
Keuntungan linked list dibandingkan dengan array kemudahan dan efektivitas kerja yang lebih baik dalam hal menambah, mengurangi, serta mencari suatu elemen/node yang terdapat dalam linked list. Hal tersebut dimungkinkan karena elemen-elemen yang terdapat pada sebuah linked list tidak ditempatkan pada sebuah blok memori komputer seperti halnya array, melainkan tiap-tiap elemen/node tersebut tersimpan dalam blok memori terpisah, penambahan, pengurangan, ataupun penggantian node dapat dilakukan dengan mengubah elemen rujukan atas tiap-tiap node yang terkait.
Linked list digunakan untuk membuat grafik
Macam-macam linked list
1. Single linked list
Single Linked List merupakan suatu linked list yang hanya memiliki satu variabel pointer saja. Dimana pointer tersebut menunjuk ke node selanjutnya. Biasanya field pada tail menunjuk ke NULL.
contoh :
struct Mahasiswa{
char nama[25];
int usia;
struct Mahasiswa *next;
}*head,*tail;
Insert (push) dan delete (pop) node pada linked list dapat dilakukan pada posisi depan (head), tengah (mid) dan belakang (tail)
2. Double linked list
Double Linked List merupakan suatu linked list yang memiliki dua variabel pointer yaitu pointer yang menunjuk ke node selanjutnya dan pointer yang menunjuk ke node sebelumnya. Setiap head dan tailnya juga menunjuk ke NULL.
contoh :
struct Mahasiwa{
char nama[25];
int usia;
struct Mahasiswa *next,*prev;
}*head,*tail;
Insert (push) dan delete (pop) node pada linked list dapat dilakukan pada posisi depan (head), tengah (mid) dan belakang (tail)
3. Circular linked list
Circular Linked List merupakan suatu linked list dimana tail (node terakhir) menunjuk ke head (node pertama). Jadi tidak ada pointer yang menunjuk NULL. Ada 2 jenis Circular Linked List, yaitu :
- Single
- Double
Single linked list
Sebuah linked list yang hanya memiliki 1 penghubung ke node lain disebut sebagai
single linked list. Di dalam sebuah linked list, ada 1 pointer yang menjadi gambaran besar, yakni pointer HEAD yang menunjuk pada node pertama di dalam linked list itu sendiri. Sebuah linked list dikatakan kosong apabila isi pointer head adalah NULL. Beberapa operasi yang biasanya ada di dalam sebuah linked list adalah:
1.
Push
Push merupakan sebuah operasi insert dimana di dalam linked list terdapat 2 kemungkinan insert, yaitu insert melalui depan (pushdepan) ataupun belakang (pushbelakang). Operasi pushdepan berarti data yang paling baru dimasukkan akan berada di depan data lainnya, dan sebaliknya pushbelakang berarti data yang paling baru akan berada di belakang data lainnya. Representasinya adalah sebagai berikut: pushdepan: 5, 3, 7, 9 maka hasilnya adalah: 9 ->7 ->3 -> 5 -> NULL pushbelakang: 5, 3, 7, 9 maka hasilnya adalah: 5 ->3 ->7 ->9 -> NULL.
2. Pop
Kebalikan dari push, merupakan operasi delete, dimana di dalam linked list memiliki 2 kemungkinan delete, yaitu melalui depan (popde
pan) dan melalui belakang (popbelakang). popdepan berarti data yang akan dihapus adalah data paling depan, dan popbelakang berarti data yang akan dihapus adalah data paling belakang (akhir). Dalam penerapan code single linked list, umumnya hanya digunakan pointer head sebagai pointer yang menunjuk pada linked list. Namun dalam pembahasan artikel ini akan digunakan 1 pointer tambahan, yakni TAIL untuk menunjuk data terakhir di dalam linked list dalam mempermudah proses pembahasan.
Double linked list
memilki pointer penunjuk 2 arah, yakni ke arah node sebelum dan node sesudah (next).
Di dalam sebuah linked list, ada 2 pointer yang menjadi penunjuk utama, yakni pointer HEAD yang menunjuk pada node pertama di dalam linked list itu sendiri dan pointer TAIL yang menunjuk pada node paling akhir di dalam linked list. Sebuah linked list dikatakan kosong apabila isi pointer head adalah NULL. Selain itu, nilai pointer prev dari HEAD selalu NULL, karena merupakan data pertama. Begitu pula dengan pointer next dari TAIL yang selalu bernilai NULL sebagai penanda data terakhir. Beberapa operasi yang biasanya ada di dalam sebuah doubly linked list pada dasarnya sama dengan yang ada di dalam single linked list, yakni:
1. Push
Push merupakan sebuah operasi insert dimana di dalam linked list terdapat 2 kemungkinan insert, yaitu insert melalui depan (pushDepan) ataupun belakang (pushBelakang). Operasi pushDepan berarti data yang paling baru dimasukkan akan berada di depan data lainnya, dan sebaliknya pushBelakang berarti data yang paling baru akan berada di belakang data lainnya. Representasinya adalah sebagai berikut: pushDepan: 5, 3, 7, 9 maka hasilnya adalah berturut-turut: 9, 7, 3, 5 pushBelakang: 5, 3, 7, 9 maka hasilnya adalah 5, 3, 7, 9.
2. Pop
Pop, kebalikan dari push, merupakan operasi delete, dimana di dalam linked list memiliki 2 kemungkinan delete, yaitu melalui depan (popDepan) dan melalui belakang (popBelakang). PopDepan berarti data yang akan dihapus adalah data paling depan, dan popBelakang berarti data yang akan dihapus adalah data paling belakang (akhir). Dalam artikel ini, pembahasan code menggunakan Bahasa Pemrograman C dengan library malloc.h.
dan void untuk print seluruh linked list adalah
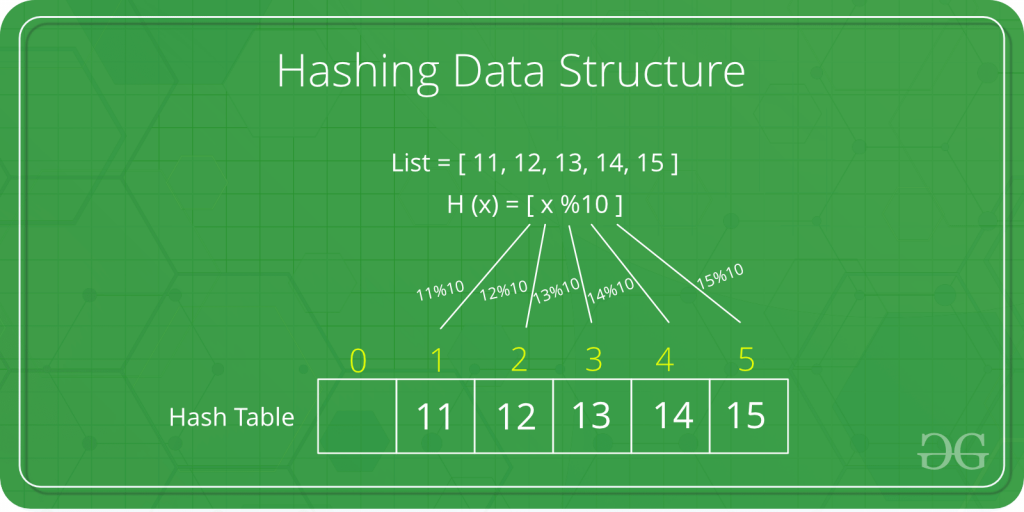
Hashing adalah transformasi string karakter menjadi nilai panjang tetap yang lebih pendek atau kunci yang mewakili string asli. Hashing digunakan untuk mengindeks dan mengambil item dalam database karena lebih cepat menemukan item menggunakan kunci hash yang lebih pendek daripada menemukannya menggunakan nilai asli. Itu juga digunakan dalam banyak algoritma enkripsi.
Algoritma hashing disebut fungsi hash – mungkin istilah tersebut berasal dari gagasan bahwa nilai hash yang dihasilkan dapat dianggap sebagai versi “campur aduk” dari nilai yang diwakili.
Selain pengambilan data yang lebih cepat, hashing juga digunakan untuk mengenkripsi dan mendekripsi tanda tangan digital (digunakan untuk mengotentikasi pengirim dan penerima pesan). Tanda tangan digital diubah dengan fungsi hash dan kemudian nilai hash (dikenal sebagai message-digest) dan tanda tangan dikirim dalam transmisi terpisah ke penerima. Menggunakan fungsi hash yang sama dengan pengirim, penerima memperoleh intisari pesan (message-digest) dari tanda tangan dan membandingkannya dengan intisari pesan yang diterima juga. (Mereka harus sama.)
Fungsi hash digunakan untuk mengindeks nilai atau kunci asli dan kemudian digunakan nanti setiap kali data yang terkait dengan nilai atau kunci tersebut akan diambil. Jadi, hashing selalu merupakan operasi satu arah. Tidak perlu “reverse engineer” fungsi hash dengan menganalisis nilai hash.
Bahkan, fungsi hash yang ideal tidak dapat diturunkan dengan analisis tersebut. Fungsi hash yang baik juga seharusnya tidak menghasilkan nilai hash yang sama dari dua input yang berbeda. Jika ya, ini dikenal sebagai collision atau tabrakan. Fungsi hash yang menawarkan risiko tabrakan yang sangat rendah dianggap dapat diterima.
Berikut adalah beberapa fungsi hash yang relatif sederhana yang telah digunakan:
- Metode pembagian-sisa : Ukuran jumlah item dalam tabel diperkirakan. Angka itu kemudian digunakan sebagai pembagi ke dalam setiap nilai atau kunci asli untuk mengekstrak hasil bagi dan sisa. Sisanya adalah nilai hash. (Karena metode ini bertanggung jawab untuk menghasilkan sejumlah tabrakan, mekanisme pencarian apa pun harus dapat mengenali tabrakan dan menawarkan mekanisme pencarian alternatif.)
- Metode lipat : Metode ini membagi nilai asli (dalam kasus ini digit) menjadi beberapa bagian, menambahkan bagian-bagian bersama-sama, dan kemudian menggunakan empat digit terakhir (atau beberapa digit angka acak lainnya yang akan berfungsi) sebagai nilai hash atau kunci.
- Metode transformasi radix: Jika nilai atau kunci digital, basis angka (atau radix) dapat diubah menghasilkan urutan digit yang berbeda. (Misalnya, kunci angka desimal dapat diubah menjadi kunci angka heksadesimal.) Angka urutan tinggi dapat dibuang agar sesuai dengan nilai hash dari panjang seragam.
- Metode penataan ulang digit: Ini hanya mengambil bagian dari nilai asli atau kunci seperti digit di posisi 3 hingga 6, membalikkan urutannya, dan kemudian menggunakan urutan digit itu sebagai nilai atau kunci hash.
Hash Table
adalah sebuah struktur data yang terdiri atas sebuah tabel dan fungsi yang bertujuan untuk memetakan nilai kunci yang unik untuk setiap record (baris) menjadi angka (hash) lokasi record tersebut dalam sebuah tabel.
Keunggulan dari struktur hash table ini adalah waktu aksesnya yang cukup cepat, jika record yang dicari langsung berada pada angka hash lokasi penyimpanannya. Akan tetapi pada kenyataannya sering sekali ditemukan hash table yang record-recordnya mempunyai angka hash yang sama (bertabrakan).
Pemetaan hash function yang digunakan bukanlah pemetaan satusatu, (antara dua record yang tidak sama dapat dibangkitkan angka hash yang sama) maka dapat terjadi bentrokan (collision) dalam penempatan suatu data record. Untuk mengatasi hal ini, maka perlu diterapkan kebijakan resolusi bentrokan (collision resolution policy) untuk menentukan lokasi record dalam tabel. Umumnya kebijakan resolusi bentrokan adalah dengan mencari lokasi tabel yang masih kosong pada lokasi setelah lokasi yang berbentrokan.
Operasi Pada Hash Tabel
- insert: diberikan sebuah key dan nilai, insert nilai dalam tabel
- find: diberikan sebuah key, temukan nilai yang berhubungan dengan key
- remove: diberikan sebuah key, temukan nilai yang berhubungan dengan key, kemudian hapus nilai tersebut
- getIterator: mengambalikan iterator,yang memeriksa nilai satu demi satu
Struktur dan Fungsi pada Hash Tabel.
Hash table menggunakan struktur data array asosiatif yang mengasosiasikan record dengan sebuah field kunci unik berupa bilangan (hash) yang merupakan representasi dari record tersebut. Misalnya, terdapat data berupa string yang hendak disimpan dalam sebuah hash table. String tersebut direpresentasikan dalam sebuah field kunci k.
Cara untuk mendapatkan field kunci ini sangatlah beragam, namun hasil akhirnya adalah sebuah bilangan hash yang digunakan untuk menentukan lokasi record. Bilangan hash ini dimasukan ke dalam hash function dan menghasilkan indeks lokasi record dalam tabel.
k(x) = fungsi pembangkit field kunci (1)
h(x) = hash function (2)
Contohnya, terdapat data berupa string “abc” dan “xyz” yang hendak disimpan dalam struktur hash table. Lokasi dari record pada tabel dapat dihitung dengan menggunakan h(k(“abc”)) dan h(k(“xyz”)).
Jika hasil dari hash function menunjuk ke lokasi memori yang sudah terisi oleh sebuah record maka dibutuhkan kebijakan resolusi bentrokan. Biasanya masalah ini diselesaikan dengan mencari lokasi record kosong
Deklarasi utama hash tabel adalah dengan struct, yaitu:
typedef struct hashtbl{
hash_size size;
struct hashnode_s **nodes;
hash_size (*hashfunc)(const char *);
}HASHTBL;
Anggota simpul pada hashtbl mempersiapkan penunjuk kepada unsur pertama yang terhubung dengan daftar. unsur ini direpresentasikan oleh struct hashnode:
struct hashnode_s {
char *key;
void *data;
struct hashnode_s *next;
};
Inisialisasi
Deklarasi untuk inisialisasi hash tabel seperti berikut:
HASHTBL *hashtbl_create(hash_size size, hash_size (*hashfunc)(const char *)){
HASHTBL *hashtbl;
if(!(hashtbl=malloc(sizeof(HASHTBL)))) return NULL;
free(hashtbl);
return NULL;
}
hashtbl->size=size;
if(hashfunc) hashtbl->hashfunc=hashfunc;
else hashtbl->hashfunc=def_hashfunc;
return hashtbl;
}
Cleanup
Hash Tabel dapat menggunakan fungsi linked lists untuk menghapus element
atau daftar anggota dari hash tabel .
Deklarasinya:
void hashtbl_destroy(HASHTBL *hashtbl){
hash_size n;
struct hashnode_s *node, *oldnode;
for(n=0; n<hashtbl->size; ++n) {
node=hashtbl->nodes[n];
while(node) {
free(node->key);
oldnode=node;
node=node->next;
free(oldnode);
}
}
free(hashtbl->nodes);
free(hashtbl);
}
Menambah Elemen Baru
Untuk menambah elemen baru maka harus menentukan ukuran pada hash tabel. Dengan deklarasi sebagai berikut:
int hashtbl_insert(HASHTBL *hashtbl, const char *key, void*data){
struct hashnode_s *node;
hash_size hash=hashtbl->hashfunc(key)%hashtbl->size;
Penambahan elemen baru dengan teknik pencarian menggunakan linked lists
untuk mengetahui ada tidaknya data dengan key yang sama yang
sebelumnya sudah dimasukkan, menggunakan deklarasi berikut:
node=hashtbl->nodes[hash];
while(node) {
if(!strcmp(node->key, key)) {
node->data=data;
return 0;
}
node=node->next;
}
Jika tidak menemukan key yang sama, maka pemasukan elemen baru pada
linked lists dengan deklarasi berikut:
if(!(node=malloc(sizeof(struct hashnode_s)))) return -1;
if(!(node->key=mystrdup(key))) {
free(node);
return -1;
}
node->data=data;
node->next=hashtbl->nodes[hash];
hashtbl->nodes[hash]=node;
return 0;
}
Menghapus sebuah elemen
Untuk menghapus sebuah elemen dari hash tabel yaitu dengan mencari nilai hash menggunakan deklarasi linked list dan menghapusnya jika nilai tersebut ditemukan. Deklarasinya sebagai berikut:
int hashtbl_remove(HASHTBL *hashtbl, const char *key){
struct hashnode_s *node, *prevnode=NULL;
hash_size hash=hashtbl->hashfunc(key)%hashtbl->size;
node=hashtbl->nodes[hash];
while(node) {
if(!strcmp(node->key, key)) {
free(node->key);
if(prevnode) prevnode->next=node->next;
else hashtbl->nodes[hash]=node->next;
free(node);
return 0;
}
prevnode=node;
node=node->next;
}
return -1;
}
Searching
Teknik pencarian pada hash tabel yaitu dengan mencari nilai hash yang sesuai menggunakan deklarasi sama seperti pada linked list. Jika data tidak
ditemukan maka menggunakan nilai balik NULL. Deklarasinya sebagai berikut:
void *hashtbl_get(HASHTBL *hashtbl, const char *key){
struct hashnode_s *node;
hash_size hash=hashtbl->hashfunc(key)%hashtbl->size;
node=hashtbl->nodes[hash];
while(node) {
if(!strcmp(node->key, key)) return node->data;
node=node->next;
}
return NULL;
}
Resizing
Jumlah elemen pada hash tabel tidak selalu diketahui ketika terjadi penambahan data. Jika jumlah elemen bertambah begitu besar maka itu akan mengurangi operasi pada hash tabel yang dapat menyebabkan terjadinya kegagalan memory. Fungsi Resizing hash tabel digunakan untuk mencegah terjadinya hal itu. Deklarasinya sebagai berikut:
int hashtbl_resize(HASHTBL *hashtbl, hash_size size){
HASHTBL newtbl;
hash_size n;
struct hashnode_s *node,*next;
newtbl.size=size;
newtbl.hashfunc=hashtbl->hashfunc;
if(!(newtbl.nodes=calloc(size, sizeof(struct hashnode_s*)))) return -1;
for(n=0; n<hashtbl->size; ++n) {
for(node=hashtbl->nodes[n]; node; node=next) {
next = node->next;
hashtbl_insert(&newtbl, node->key, node->data);
hashtbl_remove(hashtbl, node->key);
}
}
free(hashtbl->nodes);
hashtbl->size=newtbl.size;
hashtbl->nodes=newtbl.nodes;
return 0;
}
Lookup pada Hash table
Salah satu keunggulan struktur hash table dibandingkan dengan struktur tabel biasa adalah kecepatannya dalam mencari data. Terminologi lookup mengacu pada proses yang bertujuan untuk mencari sebuah record pada sebuah tabel, dalam hal ini adalah hash table.
Dengan menggunakan hash function, sebuah lokasi dari record yang dicari
bisa diperkirakan. Jika lokasi yang tersebut berisi record yang dicari, maka
pencarian berhasil. Inilah kasus terbaik dari pencarian pada hash table. Namun, jika record yang hendak dicari tidak ditemukan di lokasi yang diperkirakan, maka akan dicari lokasi berikutnya sesuai dengan kebijakan resolusi bentrokan. Pencarian akan berhenti jika record ditemukan, pencarian bertemu dengan tabel kosong, atau pencarian telah kembali ke lokasi semula.
Collision (Tabrakan)
Keterbatasan tabel hash menyebabkan ada dua angka yang jika dimasukkan ke dalam fungsi hash maka menghasilkan nilai yang sama. Hal ini disebut dengan collision.
contoh: Kita ingin memasukkan angka 6 dan 29.
Hash(6) = 6 % 23 = 6
Hash(29)= 29 % 23 = 6
Pertama-tama anggap tabel masih kosong. Pada saat angka 6 masuk akan ditempatkan pada posisi indeks 6, angka kedua 29 seharusnya ditempatkan di indeks 6 juga, namun karena indeks ke-6 sudah ditempati maka 29 tidak bisa ditempatkan di situ, di sinilah terjadi collision. Cara penanganannya bermacam-macam :
Collision Resolution Open Addressing
1. Linear Probing
Pada saat terjadi collision, maka akan mencari posisi yang kosong di bawah tempat terjadinya collision, jika masih penuh terus ke bawah, hingga ketemu tempat yang kosong. Jika tidak ada tempat yang kosong berarti HashTable sudah penuh.
2. Quadratic Probing
Penanganannya hampir sama dengan metode linear, hanya lompatannya tidak satu-satu, tetapi quadratic ( 12, 22, 32, 42, … )
3. Double Hashing
Pada saat terjadi collision, terdapat fungsi hash yang kedua untuk menentukan posisinya kembali.
Collision Resolution Chaining
1. Tambahkan key and entry di manapun dalam list (lebih mudah dari depan)
2. Kerugian:
- Overhead pada memory tinggi jika jumlah entry sedikit
3. Keunggulan dibandingkan open addressing:
- Proses insert dan remove lebih sederhana
- Ukuran Array bukan batasan (tetapi harus tetap meminimalisir collision: buat ukuran tabel sesuai dengan jumlah key dan entry yang diharapkan).
BINARY TREE
Binary Search Tree adalah sebuah konsep penyimpanan data, dimana data disimpan dalam bentuk tree yang setiap node dapat memiliki anak maksimal 2 node. Selain itu, terdapat juga aturan dimana anak kiri dari parent selalu memiliki nilai lebih kecil dari nilai parent dan anak kanan selalu memiliki nilai lebih besar dari parent. Pada artikel ini, penulis akan membahas bagaimana cara mengimplementasikan binary search tree di dalam Bahasa C.
Pertama, kita harus mempersiapkan struct yang melambangkan setiap node. Untuk contoh sederhana, struct yang dibuat disini hanya berisi 1 buah integer. Berikut adalah contoh structnya :
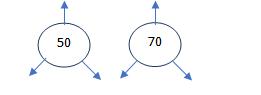
Setelah struct dibuat, kita akan membuat sebuah function yang digunakan untuk membuat node baru, seperti di bawah ini :
fungsi di atas berguna untuk membuat node baru. Jadi setiap createNode dipanggil, contoh createNode(50), createNode(70), maka akan jadi seperti ini :
setelah fungsi di atas sudah siap, berikutnya kita tinggal membuat fungsi insert/push menggunakan single pointer seperti di bawah ini :
Berikut adalah penjelasan dari code di atas :
- Pada if pertama, program akan melakukan cek pada root. Jika root bernilai NULL, artinya tree belum pernah terbentuk sama sekali. Karena itu kita tinggal melakukan malloc/ pemesanan memori pada root
- Pada else if kedua, program melakukan pengecekkan terhadap nilai baru yang mau diinsert. Jika nilai baru tersebut lebih kecil daripada node sekarang dan anak kiri dari node sekarang sedang kosong, maka program akan melakukan malloc pada anak kiri tersebut dan mengarahkan pointer parent kepada node yang sekarang.
- Pada else if ketiga, program akan melakukan pengecekkan seperti pada point 2. Hanya saja jika nilai baru tersebut lebih besar dari node sekarang dan anak kanan dari node sekarang sedang kosong, maka program akan melakukan malloc pada anak kanan tersebut dan mengarahkan pointer parent kepada node sekarang.
- Pada else if keempat, program akan jalan jika nilai baru lebih kecil dari node sekarang, tetapi anak kiri dari node tersebut tidak kosong. Maka program akan melakukan rekursif, memanggil fungsi push kembali dengan parameter nodel->left, yang berarti node sekarang dipindahkan ke anak kiri dan nilai a yang mau diinput. Sehingga pada tahap ini, suatu saat program akan menemui kondisi dimana anak kiri dari node sekarang sedang kosong.
- Pada else yang terakhir, program melakukan hal yang sama seperti point 4, hanya saja nilai yang dicek kondisinya harus lebih besar dari nilai node sekarang.
Jika kita ingin menggunakan double pointer, maka fungsi insert / push, akan jadi seperti ini :
Perbedaan cara memanggil fungsi single dan double pointer adalah seperti ini :
Contoh single : push(root,50);
Contoh double : push2(&root,50);
Jika dilihat dari code di atas, code double pointer terlihat lebih pendek karena dengan menggunakan double pointer, kita bisa melakukan passing by address. Sehingga ketika kita melakukan malloc atau memanggil newNode pada fungsi push2, maka root yang aslinya akan kena malloc juga. Berbeda dengan single pointer, jika kita melakukan node = newNode(a), maka root yang asli tidak akan ikut kena malloc, Karena ini merupakan passing by value.
Binary Tree atau Pohon Biner adalah sebuah pohon dalam struktur data yang bersifat hirarkis (hubungan one to many). Tree salah satu bentuk struktur data yang menggambarkan hubungan hierarki antar elemen-elemennya (seperti relasi one to many). Sebuah node dalam tree biasanya bisa memiliki beberapa node lagi sebagai percabangan atas dirinya.. Secara khusus, anaknya dinamakan kiri dan kanan. Binary tree tidak memiliki lebih dari tiga level dari Root.
Binary tree adalah suatu tree dengan syarat bahawa tiap node (simpul) hanya boleh memiliki maksimal dua subtree dan kedua subtree tersebut harus terpisah. Tiap node dalam binary tree boleh memiliki paling banyak dua child (anak simpul), secara khusus anaknya dinamakan kiri dan kanan.
Pohon biner dapat juga disimpan sebagai struktur data implisit dalam array, dan jika pohon tersebut merupakan sebuah pohon biner lengkap, metode ini tidak boros tempat. Dalam penyusunan yang rapat ini, jika sebuah simpul memiliki indeks i, anaknya dapat ditemukan pada indeks ke-2i+1 dan 2i+2, meskipun ayahnya (jika ada) ditemukan pada indeks lantai ((i-1)/2) (asumsikan akarnya memiliki indeks kosong).
Sebenarnya Binary Tree sama konsepnya dengan Tree. Hanya saja, kita akan mengambil sifat bilangan biner yang selalu bernilai 1 atau 0 (2 pilihan). Berarti, binary tree adalah tree yang hanya dapat mempunyai maksimal 2 percabangan saja. Untuk lebih jelasnya, lihat gambar di bawah ini.
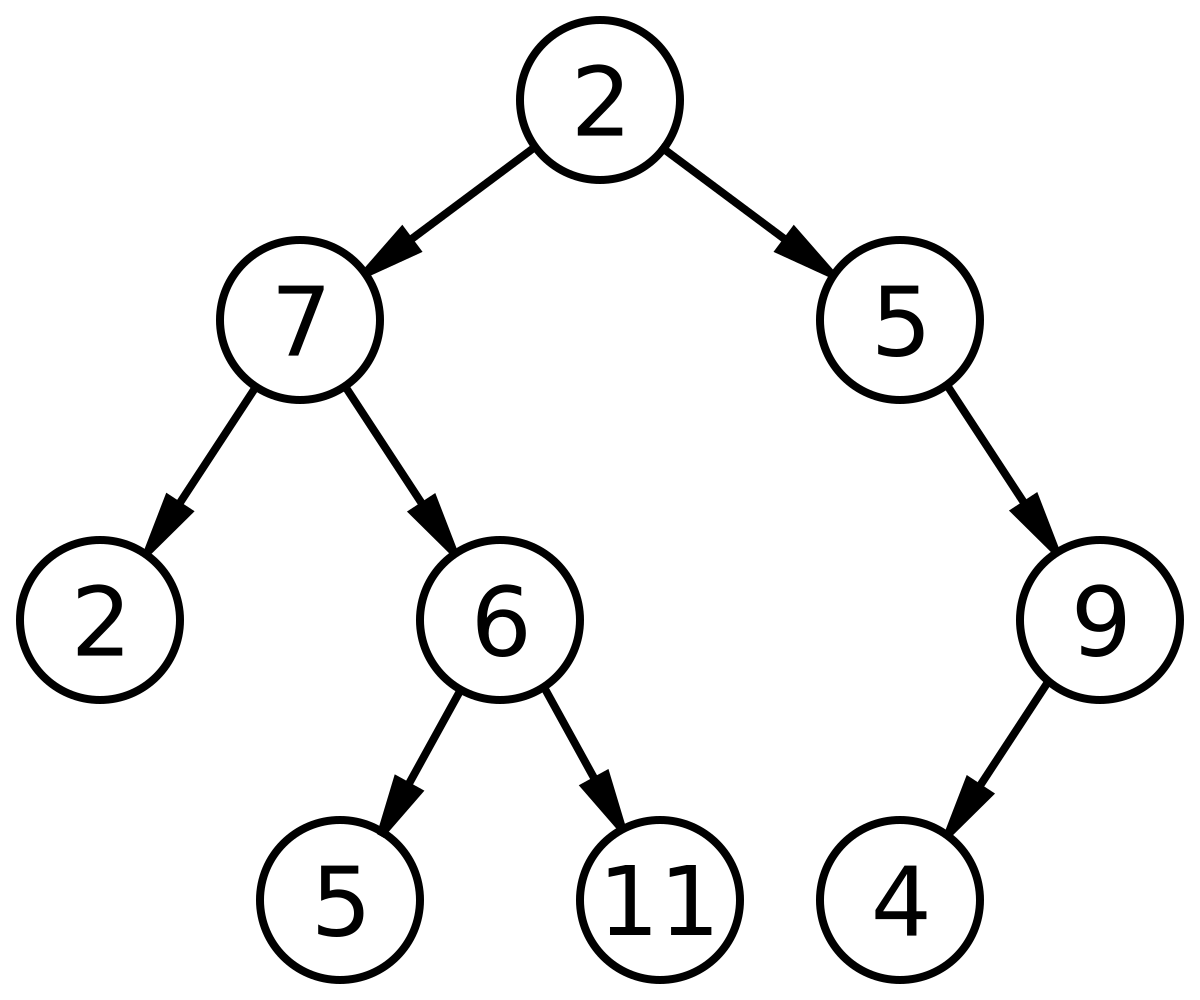
Binary Search Tree adalah tree yang terurut (ordered Binary Tree). Binary Search Tree juga sering disebut dengan Sorted Binary Tree yang berfungsi untuk menyimpan informasi nama atau bilangan yang disimpan di dalam memory. Dengan ini data dibagi menjadi dua dengan mencari titik tengah seagai patokannya. Binary tree terdiri dari simpul utama yang disebut dengan istilah root. Kemudian dari root tersebut terdapat bagian kiri dan bagian kanan. Data disimpan setelah root disimpan berdasarkan nilai perbandingan dengan root tersebut. Pengurutan dapat dilakukan bila BST ditelusuri (traversed) menggunakan metode in-order. Detail dari proses penelusuran ini akan dibahas pada pertemuan selanjutnya. Data yang telah tersusun dalam struktur data BST juga dapat dicari dengan mudah dan memiliki rata-rata kompleksitas sebesar O(log n), namun membutuhkan waktu sebesar O(n) pada kondisi terjelek dimana BST tidak berimbang dan membentuk seperti linked list.
Binary search tree memungkinkan pencarian dengan cepat, penambahan, juga menghapus data yang ada di dalamnya, bisa juga digunakan sebagai implementasi sejumlah data dinamis, atau pencarian table data dengan menggunakan informasi kunci atau key.
Agar data benar-benar tersusun dalam struktur data BST, dua aturan yang harus dipenuhi pada saat data diatur dalam BST adalah sebagai berikut:
- Semua data dibagian kiri sub-tree dari node t selalu lebih kecil dari data dalam node t itu sendiri.
- Semua data dibagian kanan sub-tree dari node t selalu lebih besar atausama dengan data dalam node t.
Pada dasarnya, operasi dalam binary search tree sama dengan operasi binary tree biasa, kecuali pada operasi insert, update, dan delete.
- Operasi insert, Pada binary search tree, insert dilakukan setelah ditemukan lokasi yang tepat (lokasi tidak ditemukan oleh user sendiri).
- Operasi search, Seperti pada binary tree biasa, namun disini update akan berpengaruh pada posisi node tersebut selanjutnya. Bila setelah diupdate mengakibatkan tree tersebut bukan binary search tree lagi, maka harus dilakukan perubahan pada tree dengan melakukan perubahan rotasi supaya tetap menjadi binary search tree.
- Operasi Delete, Seperti halnya update, delete dalam binary search tree juga turut mempengaruhi struktur dari tree tersebut. Pada operasi delete, diakukan terhadap node dengan 2 child, maka untuk menggantikannya, diambil node paling kiri dari right subtree
Lalu, ada 3 jenis cara untuk melakukan penelusuran data (traversal) pada Binary Search Tree:
- PreOrder : Print data, telusur ke kiri, telusur ke kanan
- InOrder : Telusur ke kiri, print data, telusur ke kanan
- Post Order : Telusur ke kiri, telusur ke kanan, print data
 |
| push |
 |
| pre order |
 |
| in order |
 |
| post order |
 |
| search |
~ thankyou ~
Berikut saya sertakan juga source untuk minimarket :
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include<time.h>
int pilih;
int flag = 0;
struct Market{
char name[1000];
int quantity;
long long int price;
struct Market *next, *prev;
}*head = NULL,*tail = NULL,*curr = NULL;
void pushdepan(char nameP[],int quantityP,long long int priceP){
curr = (Market*) malloc(sizeof(Market));
strcpy(curr->name,nameP);
curr->quantity = quantityP;
curr->price = priceP;
if(head==NULL){
head = tail = curr;
}else{
curr->next = head;
head->prev = curr;
head = curr;
}
tail->next = head->prev = NULL;
}
void pushbelakang(char nameP[], int quantityP, long long int priceP){
curr = (Market*) malloc(sizeof(Market));
strcpy(curr->name,nameP);
curr->quantity = quantityP;
curr->price = priceP;
if(head == NULL){
head = tail = NULL;
}else{
tail->next = curr;
curr->prev = tail;
tail = curr;
}
head->prev = tail->next = NULL;
}
void push(char nameP[], int quantityP, long long int priceP){
curr = (Market*) malloc(sizeof(Market));
strcpy(curr->name,nameP);
curr->quantity = quantityP;
curr->price = priceP;
if(head == NULL){
head = tail = curr;
}else if(strcmp(curr->name,head->name)<0){
pushdepan(nameP,quantityP,priceP);
}else if(strcmp(curr->name,tail->name)>0){
pushbelakang(nameP,quantityP,priceP);
}else{
struct Market *temp = head;
while(strcmp(temp->next->name,curr->name)<0){
temp = temp->next;
}
curr->next = temp->next;
temp->next->prev = curr;
temp->next = curr;
curr->prev = temp;
}
}
void popdepan(){
curr = head;
head = head->next;
free(curr);
head->prev = NULL;
}
void popbelakang(){
curr = tail;
tail = tail->prev;
free(curr);
tail->next = NULL;
}
void pop(char nameP[]){
if(strcmp(head->name,nameP) == 0){
popdepan();
}else if(strcmp(tail->name,nameP) == 0){
popbelakang();
}else{
struct Market *temp = head;
int x = 0;
x = strcmp(temp->next->name,nameP);
while(x!=0){
temp = temp->next;
}
curr = temp->next;
temp->next = curr->next;
curr->next->prev = temp;
free(curr);
}
}
void menu(){
printf("Welcome to DSMarket !\n");
printf("================= \n");
printf("1. Add Item\n");
printf("2. Edit Quantity\n");
printf("3. Delete Item\n");
printf("4. Print Bill\n");
printf("5. Exit\n");
printf("Choose >> ");
scanf("%d",&pilih);
getchar();
system("cls");
}
void cart(){
curr = head;
printf("=================================\n");
printf("| Nama Barang | Jumlah |\n");
printf("=================================\n");
while(curr!=NULL){
printf("| %-20s | %-6d |\n",curr->name,curr->quantity);
curr = curr->next;
}
printf("=================================\n");
}
void addItem(){
char namaProduk[1000];
int kuantitas;
long long int price;
do{
flag = 1;
printf("Product's name : ");
scanf("%[^\n]",&namaProduk); getchar();
curr = head;
while(curr != NULL){
flag = strcmp(curr->name,namaProduk);
curr = curr->next;
if (flag == 0){
printf("Product already exist!\n");
break;
}
}
}while(flag==0);
printf("Product's quantity : ");
scanf("%d",&kuantitas); getchar();
//random
price = (rand()%100)*1000;
push(namaProduk,kuantitas,price);
printf("Item Added!..\n");
printf("Press enter to continue");
getchar();
system("cls");
}
void edit(char nameP[], int quantityP, long long int priceP){
struct Market *cari = head;
while(cari != NULL){
if(strcmp(cari->name,nameP) == 0){
cari->quantity = quantityP;
cari->price = priceP;
break;
}
cari = cari->next;
}
}
void editKuantitas(){
char namaProduk[1000];
int kuantitas;
long long int price;
curr = head;
if(curr == NULL){
printf("Please add product first!\n");
printf("Press enter to continue");
getchar();
system("cls");
}else{
cart();
do{
flag = 0;
printf("Input product's name to edit : ");
scanf("%[^\n]",&namaProduk); getchar();
curr = head;
while(curr != NULL){
flag = strcmp(curr->name,namaProduk);
curr = curr->next;
if(flag == 0){
break;
}
}
}while(flag!=0);
if(flag!=0) printf("Product doesn't exist!\n");
printf("Input desired quantity : ");
scanf("%d",&kuantitas); getchar();
price = (rand()%100)*1000;
edit(namaProduk,kuantitas,price);
printf("Edit Success!..\n");
printf("Press enter to continue");
getchar();
system("cls");
}
}
void hapus(){
char namaProduk[1000];
curr = head;
if(curr == NULL){
printf("Please add product first!\n");
printf("Press enter to continue");
getchar();
system("cls");
}else{
cart();
do{
flag = 0;
printf("Input product's name to delete : ");
scanf("%[^\n]",&namaProduk); getchar();
curr = head;
while(curr != NULL){
flag = strcmp(curr->name,namaProduk);
curr = curr->next;
if(flag == 0){
break;
}
}
}while(flag!=0);
if(flag != 0) printf("Product doesn't exist!\n");
pop(namaProduk);
printf("Delete Success!..\n");
printf("Press enter to continue");
getchar();
system("cls");
}
}
void print(){
//untuk bill
curr = head;
if(curr == NULL){
printf("Please add product first!\n");
printf("Press enter to continue");
getchar();
system("cls");
}else{
printf(" DSMarket\n");
printf("=========================================================\n");
printf("| Nama Barang | Jumlah | Harga | Total |\n");
printf("=========================================================\n");
while(curr!=NULL){
long long int total = curr->quantity*curr->price;
printf("| %-20s | %-6d | %-9lld | %-9lld |\n",curr->name,curr->quantity,curr->price,total);
curr = curr->next;
}
printf("=========================================================\n");
printf("\nGrand Total = Kindness is Free\n");
printf(" ~Thankyou~\n\n");
printf("Press enter to continue");
getchar();
system("cls");
}
}
int main(){
do{
menu();
if(pilih == 1){
addItem();
}else if(pilih == 2){
editKuantitas();
}else if(pilih == 3){
hapus();
}else if(pilih == 4){
print();
}
}while(pilih != 5);
return 0;
}